week 2 web design
This week marks the first week of our workshop. We are all a bit unfamiliar with the digital practice-related content at the moment.
We started with web page creation. Although I had taken relevant courses and created some simple web pages during my undergraduate years,
I haven't practiced much since then, and the web design software I used back then was different. As a result, the initial process of
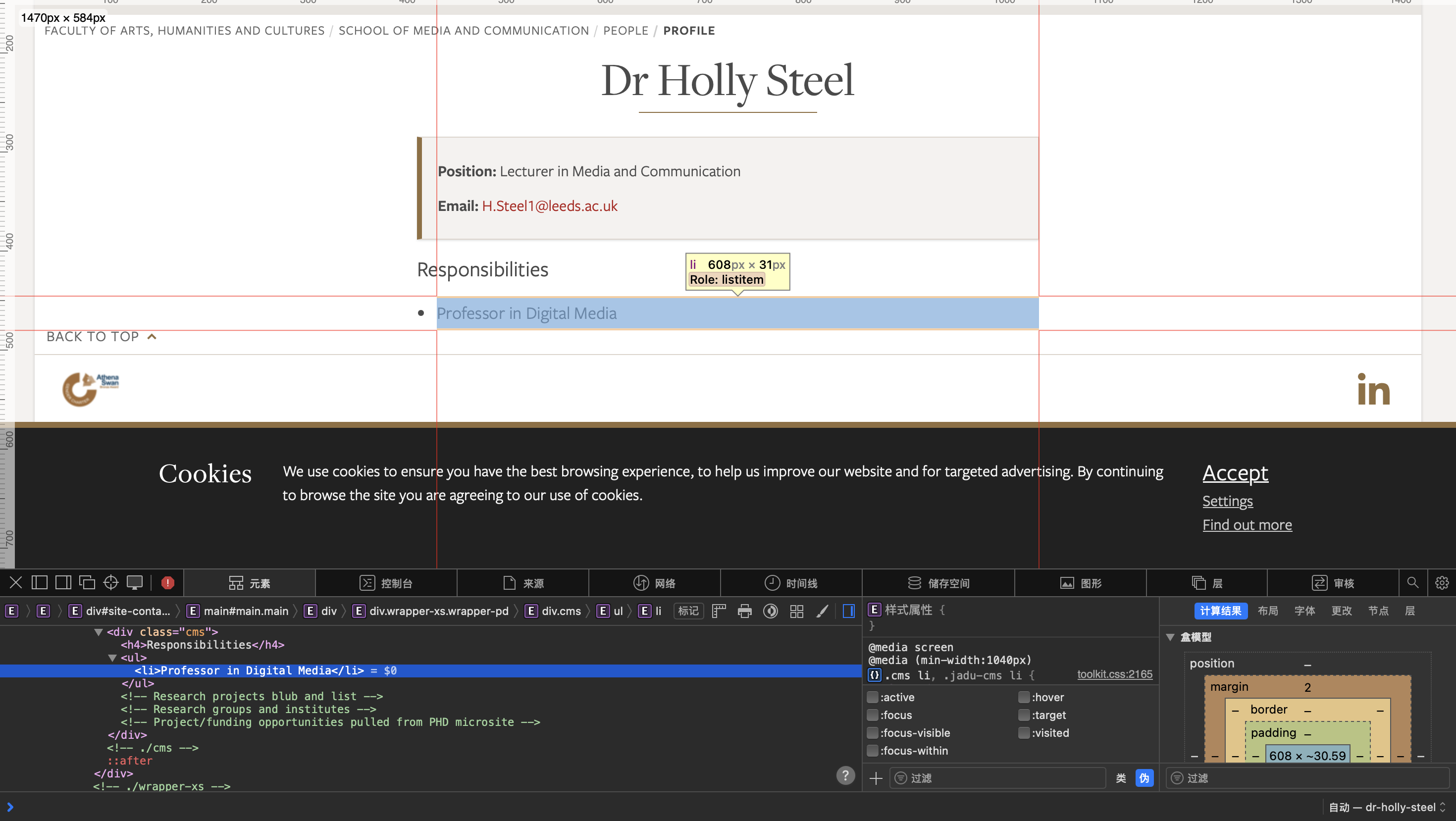
setting up the web page was a bit bumpy. However, the subsequent code writing and using web inspection tools to view and modify the
web page went relatively smoothly. During this process, I also had some thoughts. Web inspection tools, on the one hand, can help web
page creators conveniently view the source code and make changes when problems occur. They are also beneficial
for us web page creation learners to refer to and learn from high-quality web page source codes. But at the same time, on the other
hand, through web inspection tools, we can also change the code to alter the presentation of the web page, including text, images,
and all web page content. Although this is a superficial change and the web page won't have any substantial changes after refreshing
and saving, for some people with ulterior motives, they can use this method to modify the web page and take screenshots to deceive
some ordinary people who are not familiar with this field, which may lead to some adverse consequences. Therefore, we need to use
this technology carefully and correctly.
week 3 webscrap
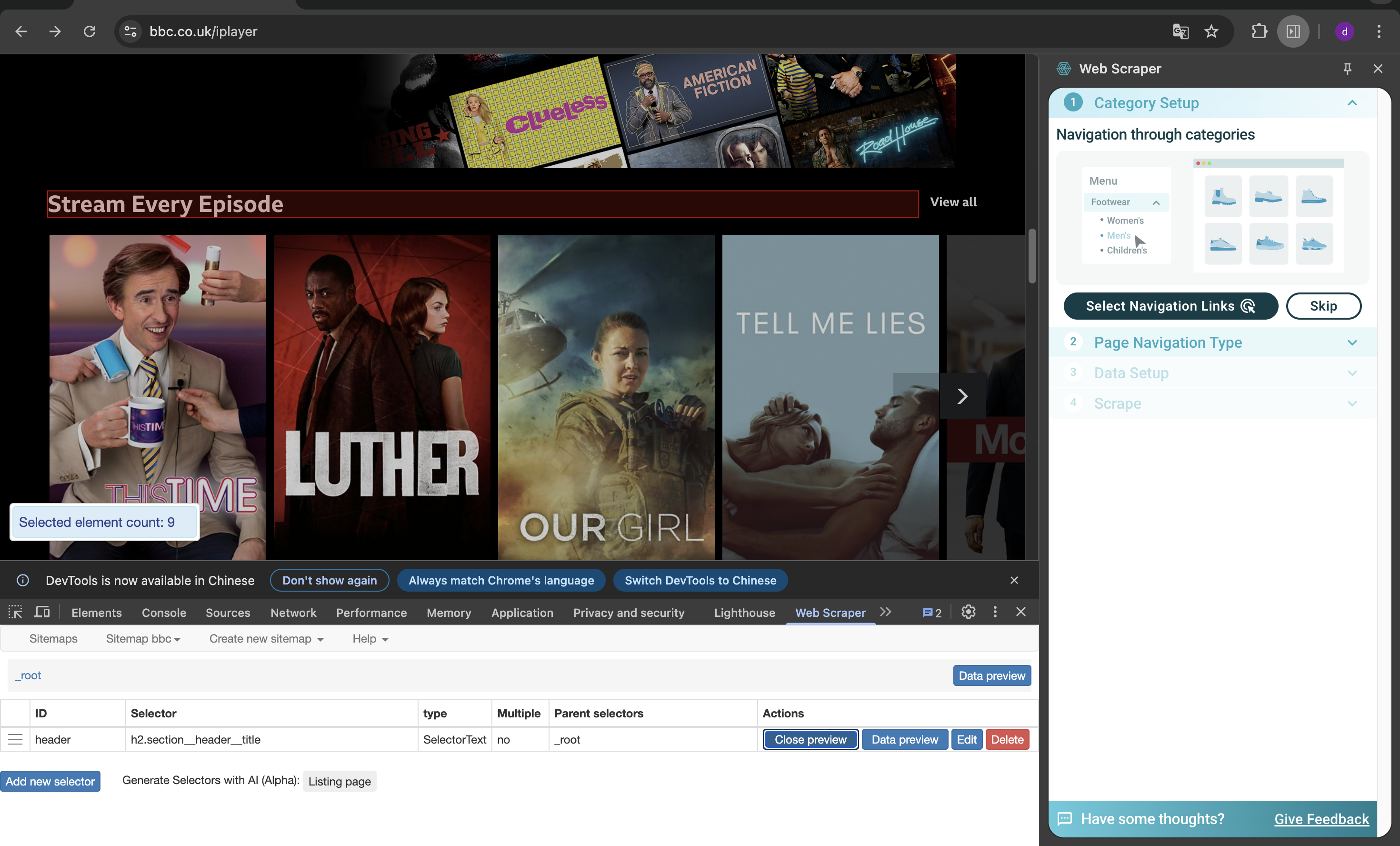
This week, based on our existing understanding of web page code, we further studied web scraping technology. Web scraping refers
to the use of automated programs to extract data from websites. It is a common method in data science, market research, public
opinion analysis, AI training, and news investigation. Through various web scraping tools, we can more efficiently find the code
we need and better count the information on web pages. From a critical perspective, web scraping seemingly realizes information
freedom, but in fact, it intensifies the inequality of data power - large institutions dominate data collection with resources
and algorithms, while individuals and small websites passively become "data sources". The selection and filtering during the
scraping process also hide biases, determining which content is considered valuable and which is excluded. Moreover, scraping
often infringes on privacy, ignores contextual consent, and incorporates users into surveillance systems without their knowledge.
It not only reflects the plundering of information by digital capitalism but also the contemporary society's reliance on
"scrapability": only what can be read by machines is regarded as existing. Therefore, web scraping is not just a technical issue,
but a convergence point of knowledge, power, and ethics - it requires us to rethink the balance between information openness and
individual dignity in the data age.
week 4 Data Collection
This week, we delved into data-related knowledge and learned that for the same topic, different perspectives require different
data, and the data collection thinking process varies accordingly. Data is never neutral. Researchers "produce" a specific data
reality through problem setting, classification methods, participant selection, and other steps. Data collection is closely
related to power - who defines the research question, what is considered "use", and whose voices are included or excluded all
shape the data itself. Our group was assigned scenario 3, which is a research-led approach as an academic researcher at a
UK-based university, interested in learning about how students use generative AI as part of their daily lives. Our research
goal was to understand usage habits. At the beginning of the research, we spent a considerable amount of time analyzing and
discussing our positioning and topic focus. Since generative AI is a broad concept and students' daily lives are also a vast
scope, we eventually narrowed it down to students' homework, study, and writing. After that, we analyzed the aspect of "how
students use", considering the meaning of "use" in terms of frequency, purpose, whether students indicate their use of AI
behavior patterns, the most commonly used software, attitudes towards use and its impact, etc. We ultimately selected the
five most important questions to design the questionnaire. Through this process, I also discovered that it is very difficult
to design questions that are specific enough to generate meaningful data while remaining neutral and non-judgmental, especially
when it comes to issues of academic integrity. As a researcher, you must balance research interests and participant protection,
and not make students feel like they are being "checked for cheating". From the perspective of data collection, students are
also reluctant to reveal their true thoughts and usage habits when it involves academic integrity.
week 5 data visualization
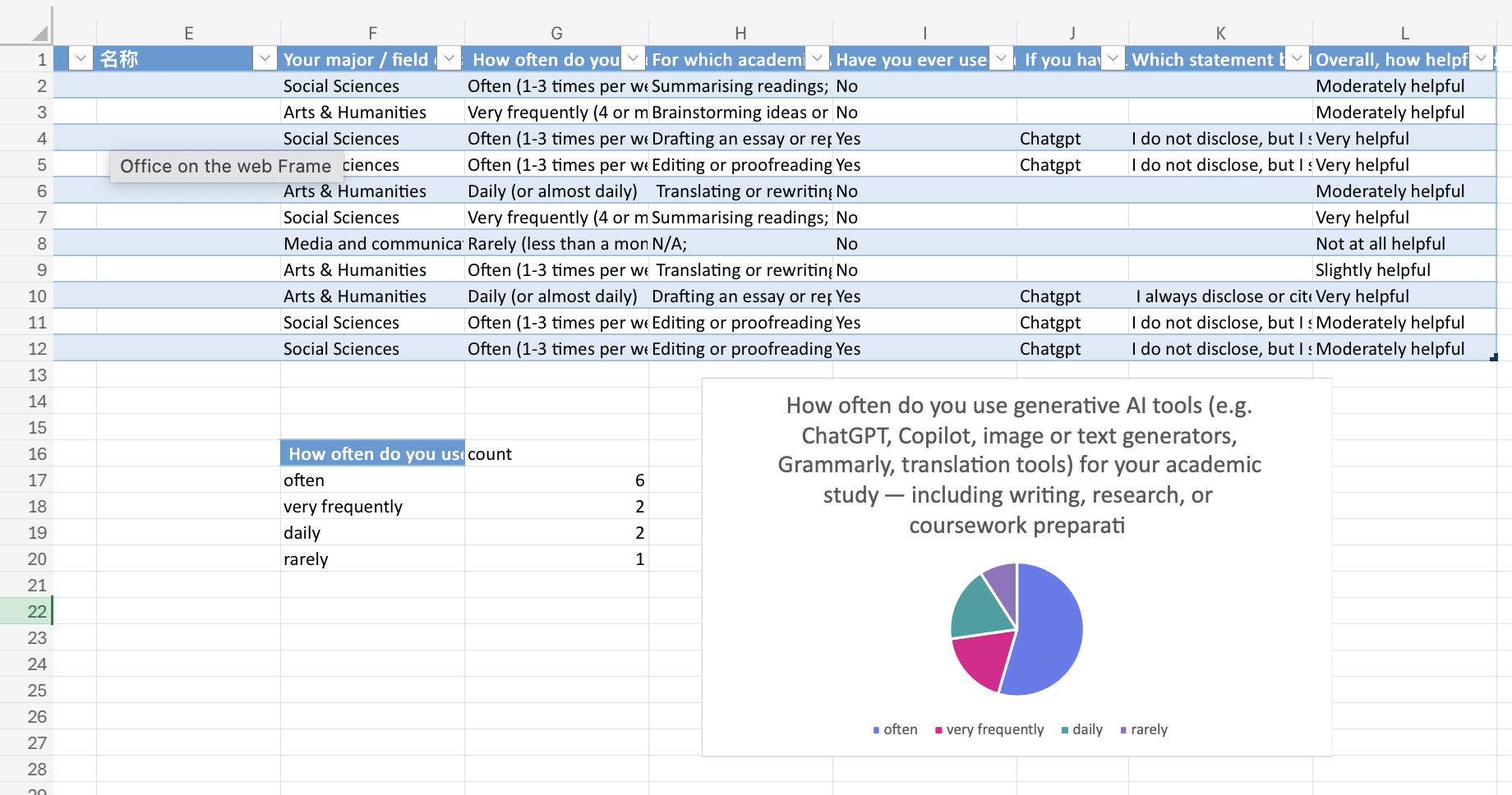
This week, we made a visual analysis of the questionnaire data collected last week, mainly through pie charts and line charts in Excel,
but due to the small number of questionnaires collected, we found that it was difficult to draw general conclusions, and less useful
information was collected. In the face of different visual audiences, we chose to The content of the visualisation will also be
different, and the conclusions may be different. Therefore, visualisation is both analytical and interpretive.Charts do not simply
“show” data — they mediate it. They turn abstract patterns into persuasive arguments.
week 6 Identity, Algorithmic Identity, and Data
This week, we learned what the algorithm is and its impact on our identity recognition on social media. Our algorithmic identity will
change dynamically over time. First of all, we find the privacy permission content on the ins platform, understand what information
the algorithm will collect and analyse about us, and then constantly infer our identity and preferences, and recommend new content
that we may be interested in, especially some advertising and marketing. Our algorithm identity is a class that we have never selected.
Don't shape simplified and commercialised advertising objects. Although the algorithm can derive our identity and preferences by
analysing the equal quantitative data of our likes and collections, it sometimes makes mistakes in positioning, because our true
emotions cannot be calculated, and our preferences have been changing all the time.

week 7
week 8
week 9
week 10
